Incremental Change
Incremental change [1] is a process that adds new functionality and new properties to software. Its an essential part of software processes such as maintenance, evolution, iterative development and enhancements, and agile development. Because of that, it plays an important role in practical software engineering.
JRipples concentrates on IC in the context of object-oriented Java programs and selected IC activities. Because change requests are formulated in terms of program concepts
chunks of knowledge about the program and application domainthe resulting IC activities also focus on program concepts. Moreover, most change requests originate from the
end user, so the end users view of the program is the source of most concepts that govern IC. Additional concepts might originate from other programmers and deal with the
program architecture or algorithms. Program dependencies also play a crucial role in IC; if a program component changes, other dependent components might also have to change. This is true even for well-designed object-oriented programs.
The main activities of our IC model are summarized in the figure to the left.
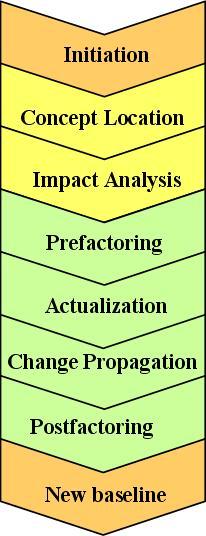 In this model, IC is initiated with a change request that originates with a customer or other project stakeholder, who requests new functionality to be incorporated into an existing system. A change request may take the form of a bug report, which requires a certain functionality to be corrected, or it may stipulate a completely new functionality that is demanded by changing business or technological needs.
In this model, IC is initiated with a change request that originates with a customer or other project stakeholder, who requests new functionality to be incorporated into an existing system. A change request may take the form of a bug report, which requires a certain functionality to be corrected, or it may stipulate a completely new functionality that is demanded by changing business or technological needs.
The next two activities of IC are concept location and impact analysis and are undertaken before the actual change is introduced into the system; hence, they constitute a design phase of IC.
Concept location allows the programmers to determine the initial location of the change within the source code. Typically, concepts appear as nouns, verbs, or short clauses in the change request. These concepts are also embedded within the structures of the source code and appear as variables, classes, or methods. Concept location is the process that finds the implementations of these concepts [2]. Effective concept location techniques are crucial for software engineers since they provide the means for evolving large software systems without understanding the entire body of the code [3] and identify the place in the software where the change is to be made.
We distinguish two types of concepts: explicit and implicit. Explicit concepts are directly implemented in the code as variables, snippets of executable code, methods, classes, and so forth. Implicit concepts are assumptions that underlie parts of a code but not but are not directly implemented. For example, many applications assume there is only one user who is working with them and there is no specific code that can be identified as an implementation of this single user concept. If in a process of maintenance such an application is required to support multiple users, programmers would have to change the implicit concept of the user to the explicit one and this change requires a substantial effort [1]. Depending on the type of concepts, different concept location techniques may be applied.
After concept location, the programmers proceed with the next activity, which is impact analysis. Impact analysis determines a changes extent by sketching out the strategy for the change and identifying the set of classes that the IC affects, called the impact set.
The next activities of IC implement the desired change. These activities are prefactoring, actualization, change propagation and postfactoring. In addition, testing activity is undertaken throughout each of these four activities to ensure quality of the software.
Refactoring is an activity that restructures the architecture of a program without changing its functionality [4]. We distinguish two kinds of refactoring: prefactoring and postfactoring. Prefactoring is an opportunistic refactoring that takes place before the change proper in order to facilitate the inclusion of a new functionality within the existing code. For explicit concepts that are implemented as dispersed snippets of code, extract class [4] prefactoring may organize these snippets into new classes thus localizing modifications and minimizing the impact of the change.
On the other hand, postfactoring refactors the resulting new and old code after the change was implemented. It removes all anti-patterns, introduced to the code, and makes the system clearer and more understandable in the future evolution. In the projects, students were encouraged to use refactoring tools that are available in many software development environments.
Actualization is the activity that implements the new code and, if necessary, connects it to the existing code. In the case of implicit concepts, actualization creates new classes then connects them to the rest of the system by creating instances of these classes in the places that were identified by concept location. In the case of explicit concepts, actualization alters the code, extracted into the separate class during prefactoring process.
After the new code has been incorporated into the software system, the system may or may not become inconsistent. In order to return the system back to a consistent state, change propagation changes all classes in the former system that have become a source of inconsistencies. This activity is similar to impact analysis, and it iteratively visits dependent and supporting classes making actual code updates as the process proceeds [5].
Unit and functional testing is performed to ensure that all classes affected by the change and the new functionality are correct. It also ensures refactoring doesnt break the system. Regression testing assures that the old functionality remains intact after a change has taken place [6], while test cases, created as part of actualization process, are used to check correctness of the new functionality.
Finally, after the changed source code is thoroughly tested, it is checked into version control system and forms a new baseline for future updates.
References
- [1] Rajlich, V. and Gosavi, P., "Incremental Change in Object-Oriented Programming", in IEEE Software, 2004, pp. 2-9.
- [2] Rajlich, V. and Wilde, N., "The Role of Concepts in Program Comprehension", in Proceedings of IEEE International Workshop on Program Comprehension (IWPC'02), 2002, pp. 271-278.
- [3] Marcus, A., Rajlich, V., Buchta, J., Petrenko, M., and Sergeyev, A., "Static Techniques for Concept Location in Object-Oriented Code", in Proceedings of 13th IEEE International Workshop on Program Comprehension (IWPC'05), 2005, pp. 33-42.
- [4] Fowler, M., Beck, K., Brant, J., Opdyke, W., and Roberts, D., Refactoring: Improving the Design of Existing Code. Reading, MA: Addison Wesley, 1999.
- [5] Rajlich, V., "A Model for Change Propagation Based on Graph Rewriting", in Proceedings of IEEE International Conference on Software Maintenance (ICSM'97), 1997, pp. 84-91.
- [6] Skoglund, M. and Runeson, P., "A Case Study on Regression Test Suite Maintenance in System Evolution", in Proceedings of 20th IEEE International Conference on Software Maintenance (ICSM'04), Chicago, Illinois, 2004, pp. 11-14.